еЬ®гАКжХ∞жНЃеЇУеОЯзРЖгАЛйЗМйЭҐпЉМеѓєиБЪз∞З糥еЉХзЪДиІ£йЗКжШѓ:иБЪз∞З糥еЉХзЪДй°ЇеЇПе∞±жШѓжХ∞жНЃзЪДзЙ©зРЖе≠ШеВ®й°ЇеЇПпЉМиАМеѓєйЭЮиБЪз∞З糥еЉХзЪДиІ£йЗКжШѓ:糥еЉХй°ЇеЇПдЄОжХ∞жНЃзЙ©зРЖжОТеИЧй°ЇеЇПжЧ†еЕ≥гАВж≠£еЉПеЫ†дЄЇе¶Вж≠§пЉМжЙАдї•дЄАдЄ™и°®жЬАе§ЪеП™иГљжЬЙдЄАдЄ™иБЪз∞З糥еЉХгАВ
дЄНињЗињЩдЄ™еЃЪдєЙ姙жКљи±°дЇЖгАВеЬ®SQL ServerдЄ≠пЉМ糥еЉХжШѓйАЪињЗдЇМеПЙж†СзЪДжХ∞жНЃзїУжЮДжЭ•жППињ∞зЪДпЉМжИСдїђеПѓдї•ињЩдєИзРЖиІ£иБЪз∞З糥еЉХпЉЪ糥еЉХзЪДеПґиКВзВєе∞±жШѓжХ∞жНЃиКВзВєгАВиАМйЭЮиБЪз∞З糥еЉХзЪДеПґиКВзВєдїНзДґж؃糥еЉХиКВзВєпЉМеП™дЄНињЗжЬЙдЄАдЄ™жМЗйТИжМЗеРСеѓєеЇФзЪДжХ∞жНЃеЭЧгАВе¶ВдЄЛеЫЊпЉЪ
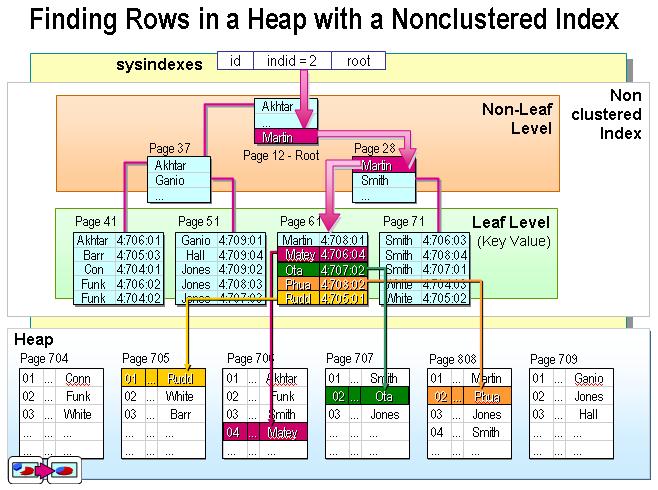
йЭЮиБЪз∞З糥еЉХ
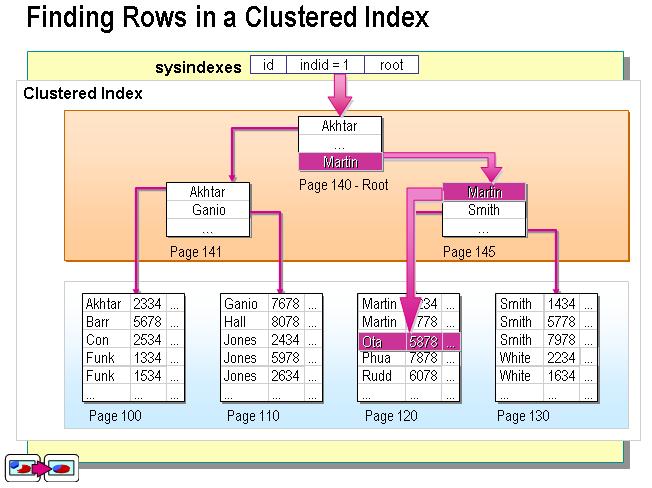
иБЪз∞З糥еЉХ
иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХзЪДжЬђиі®еМЇеИЂеИ∞еЇХжШѓдїАдєИпЉЯдїАдєИжЧґеАЩзФ®иБЪз∞З糥еЉХпЉМдїАдєИжЧґеАЩзФ®йЭЮиБЪз∞З糥еЉХпЉЯ
ињЩжШѓдЄАдЄ™еЊИе§НжЭВзЪДйЧЃйҐШпЉМеЊИйЪЊзФ®дЄЙи®АдЄ§иѓ≠иѓіжЄЕж•ЪгАВжИСеЬ®ињЩйЗМдїОSQL Server糥еЉХдЉШеМЦжߕ胥зЪДиІТеЇ¶зЃАеНХи∞Ии∞И(е¶ВжЮЬеѓєињЩжЦєйЭҐжДЯеЕіиґ£зЪДиѓЭпЉМеПѓдї•иѓїдЄАиѓїеЊЃиљѓеЗЇзЙИзЪДгАКMicrosoft SQL Server 2000жХ∞жНЃеЇУзЉЦз®ЛгАЛзђђ3еНХеЕГзЪДжХ∞жНЃзїУжЮДеЉХиЃЇдї•еПКзђђ6гАБ13гАБ14еНХеЕГ)гАВ
и¶БеїЇзЂЛдЄАдЄ™иБЪз∞З糥еЉХпЉМеПѓдї•дљњзФ®еЕ≥йФЃе≠ЧCLUSTEREDпЉЪCREATECLUSTEREDINDEXmycolumn_clust_indexONmytable(mycolumn)
и¶БеїЇзЂЛдЄАдЄ™йЭЮиБЪз∞З糥еЉХCREATEINDEXmycolumn_indexONmytable(myclumn)
дЄАгАБ糥еЉХеЭЧдЄОжХ∞жНЃеЭЧзЪДеМЇеИЂ
е§ІеЃґйГљзЯ•йБУпЉМ糥еЉХеПѓдї•жПРйЂШж£А糥жХИзОЗпЉМеЫ†дЄЇеЃГзЪДдЇМеПЙж†СзїУжЮДдї•еПКеН†зФ®з©ЇйЧіе∞ПпЉМжЙАдї•иЃњйЧЃйАЯеЇ¶еЭЧгАВиЃ©жИСдїђжЭ•зЃЧдЄАйБУжХ∞е≠¶йҐШпЉЪе¶ВжЮЬи°®дЄ≠зЪДдЄАжЭ°иЃ∞ељХеЬ®з£БзЫШдЄКеН†зФ®1000е≠ЧиКВзЪДиѓЭпЉМжИСдїђеѓєеЕґдЄ≠10е≠ЧиКВзЪДдЄАдЄ™е≠ЧжЃµеїЇзЂЛ糥еЉХпЉМйВ£дєИиѓ•иЃ∞ељХеѓєеЇФзЪД糥еЉХеЭЧзЪДе§Іе∞ПеП™жЬЙ10е≠ЧиКВгАВжИСдїђзЯ•йБУпЉМSQL ServerзЪДжЬАе∞Пз©ЇйЧіеИЖйЕНеНХеЕГжШѓвАЬй°µпЉИPageпЉЙвАЭпЉМдЄАдЄ™й°µеЬ®з£БзЫШдЄКеН†зФ®8Kз©ЇйЧіпЉМйВ£дєИињЩдЄАдЄ™й°µеПѓдї•е≠ШеВ®дЄКињ∞иЃ∞ељХ8жЭ°пЉМдљЖеПѓдї•е≠Ше®糥еЉХ800жЭ°гАВзО∞еЬ®жИСдїђи¶БдїОдЄАдЄ™жЬЙ8000жЭ°иЃ∞ељХзЪДи°®дЄ≠ж£А糥琶еРИжЯРдЄ™жЭ°дїґзЪДиЃ∞ељХпЉМе¶ВжЮЬж≤°жЬЙ糥еЉХзЪДиѓЭпЉМжИСдїђеПѓиГљйЬАи¶БйБНеОЖ8000жЭ°√Ч1000е≠ЧиКВ/8Kе≠ЧиКВ=1000дЄ™й°µйЭҐжЙНиГље§ЯжЙЊеИ∞зїУжЮЬгАВе¶ВжЮЬеЬ®ж£А糥е≠ЧжЃµдЄКжЬЙдЄКињ∞糥еЉХзЪДиѓЭпЉМйВ£дєИжИСдїђеПѓдї•еЬ®8000жЭ°√Ч10е≠ЧиКВ/8Kе≠ЧиКВ=10дЄ™й°µйЭҐдЄ≠е∞±ж£А糥еИ∞жї°иґ≥жЭ°дїґзЪД糥еЉХеЭЧпЉМзДґеРОж†єж́糥еЉХеЭЧдЄКзЪДжМЗйТИйАРдЄАжЙЊеИ∞зїУжЮЬжХ∞жНЃеЭЧпЉМињЩж†ЈIOиЃњйЧЃйЗПи¶Бе∞СзЪДе§ЪгАВ
дЇМгАБ糥еЉХдЉШеМЦжКАжЬѓ
жШѓдЄНжШѓжЬЙ糥еЉХе∞±дЄАеЃЪж£А糥зЪДењЂеСҐпЉЯз≠Фж°ИжШѓеР¶гАВжЬЙдЇЫжЧґеАЩзԮ糥еЉХињШдЄНе¶ВдЄНзԮ糥еЉХењЂгАВжѓФе¶ВиѓіжИСдїђи¶Бж£А糥дЄКињ∞и°®дЄ≠зЪДжЙАжЬЙиЃ∞ељХпЉМе¶ВжЮЬдЄНзԮ糥еЉХпЉМйЬАи¶БиЃњйЧЃ8000жЭ°√Ч1000е≠ЧиКВ/8Kе≠ЧиКВ=1000дЄ™й°µйЭҐпЉМе¶ВжЮЬдљњзԮ糥еЉХзЪДиѓЭпЉМй¶ЦеЕИж£А糥糥еЉХпЉМиЃњйЧЃ8000жЭ°√Ч10е≠ЧиКВ/8Kе≠ЧиКВ=10дЄ™й°µйЭҐеЊЧеИ∞糥еЉХж£А糥зїУжЮЬпЉМеЖНж†єж́糥еЉХж£А糥зїУжЮЬеОїеѓєеЇФжХ∞жНЃй°µйЭҐпЉМзФ±дЇОжШѓж£А糥жЙАжЬЙжХ∞жНЃпЉМжЙАдї•йЬАи¶БеЖНиЃњйЧЃ8000жЭ°√Ч1000е≠ЧиКВ/8Kе≠ЧиКВ=1000дЄ™й°µйЭҐе∞ЖеЕ®йГ®жХ∞жНЃиѓїеПЦеЗЇжЭ•пЉМдЄАеЕ±иЃњйЧЃдЇЖ1010дЄ™й°µйЭҐпЉМињЩжШЊзДґдЄНе¶ВдЄНзԮ糥еЉХењЂгАВ
SQL ServerеЖЕйГ®жЬЙдЄАе•ЧеЃМжХізЪДжХ∞жНЃж£А糥дЉШеМЦжКАжЬѓпЉМеЬ®дЄКињ∞жГЕеЖµдЄЛпЉМSQL ServerзЪДжߕ胥聰еИТпЉИSearch PlanпЉЙдЉЪиЗ™еК®дљњзФ®и°®жЙЂжППзЪДжЦєеЉПж£А糥жХ∞жНЃиАМдЄНдЉЪдљњзФ®дїїдљХ糥еЉХгАВйВ£дєИSQL ServerжШѓжАОдєИзЯ•йБУдїАдєИжЧґеАЩзԮ糥еЉХпЉМдїАдєИжЧґеАЩдЄНзԮ糥еЉХзЪДеСҐпЉЯSQL ServerйЩ§дЇЖжЧ•еЄЄзїіжК§жХ∞жНЃдњ°жБѓе§ЦпЉМињШзїіжК§зЭАжХ∞жНЃзїЯиЃ°дњ°жБѓпЉМдЄЛеЫЊжШѓжХ∞жНЃеЇУе±ЮжАІй°µйЭҐзЪДдЄАдЄ™жИ™еЫЊпЉЪ
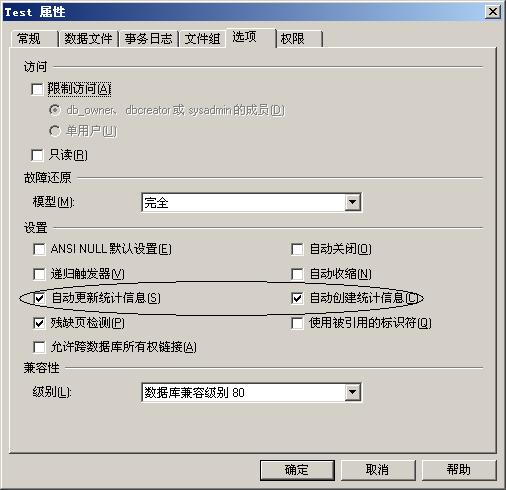
дїОеЫЊдЄ≠жИСдїђеПѓдї•зЬЛеИ∞пЉМSQL ServerиЗ™еК®зїіжК§зїЯиЃ°дњ°жБѓпЉМињЩдЇЫзїЯиЃ°дњ°жБѓеМЕжЛђжХ∞жНЃеѓЖеЇ¶дњ°жБѓдї•еПКжХ∞жНЃеИЖеЄГдњ°жБѓпЉМињЩдЇЫдњ°жБѓеЄЃеК©SQL ServerеЖ≥еЃЪе¶ВдљХеИґеЃЪжߕ胥聰еИТдї•еПКжߕ胥жШѓжШѓеР¶дљњзԮ糥еЉХдї•еПКдљњзФ®дїАдєИж†ЈзЪД糥еЉХпЉИињЩйЗМе∞±дЄНеЖНиІ£йЗКеЃГдїђеИ∞еЇХе¶ВдљХеЄЃеК©SQL ServerеїЇзЂЛжߕ胥聰еИТзЪДдЇЖпЉЙгАВжИСдїђињШжШѓжЭ•еБЪдЄ™еЃЮй™МгАВеїЇзЂЛдЄАеЉ†и°®пЉЪtabTest(ID, unqValueпЉМintValue)пЉМеЕґдЄ≠IDжШѓжճ嚥иЗ™еК®зЉЦеϣ䪿糥еЉХпЉМunqValueжШѓuniqueidentifierз±їеЮЛпЉМеЬ®дЄКйЭҐеїЇзЂЛжЩЃйАЪ糥еЉХпЉМintValue жШѓжճ嚥пЉМдЄНеїЇзЂЛ糥еЉХгАВдєЛжЙАдї•жМВдЄКдЄАдЄ™ж≤°жЬЙ糥еЉХзЪДintValueе≠ЧжЃµпЉМе∞±жШѓйШ≤ж≠ҐSQL
ServerдљњзԮ糥еЉХи¶ЖзЫЦжߕ胥дЉШеМЦжКАжЬѓпЉМињЩж†ЈеЃЮй™Ме∞±иµЈдЄНеИ∞дљЬзФ®дЇЖгАВеРСи°®дЄ≠ељХеЕ•10000жЭ°йЪПжЬЇиЃ∞ељХпЉМдї£з†Бе¶ВдЄЛпЉЪ
 CREATETABLE[dbo].[tabTest](
CREATETABLE[dbo].[tabTest](
[ID][int]IDENTITY(1,1)NOTNULL,
[unqValue][uniqueidentifier]NOTNULL,
[intValue][int]NOTNULL
)ON[PRIMARY]
GO
ALTERTABLE[dbo].[tabTest]WITHNOCHECKADD
CONSTRAINT[PK_tabTest]PRIMARYKEYCLUSTERED
(
[ID]
)ON[PRIMARY]
GO
ALTERTABLE[dbo].[tabTest]ADD
CONSTRAINT[DF_tabTest_unqValue]DEFAULT(newid())FOR[unqValue]
GO
CREATEINDEX[IX_tabTest_unqValue]ON[dbo].[tabTest]([unqValue])ON[PRIMARY]
GO
declare@iint
declare@vint
set@i=0
while@i<10000
begin
set@v=rand()*1000
insertintotabTest([intValue])values(@v)
set@i=@i+1
end
зДґеРОжИСдїђжЙІи°МдЄ§дЄ™жߕ胥庴жЯ•зЬЛжЙІи°МиЃ°еИТпЉМе¶ВеЫЊпЉЪпЉИеЬ®жߕ胥еИЖжЮРеЩ®зЪДжߕ胥иПЬеНХдЄ≠еПѓдї•жЙУеЉАжߕ胥聰еИТпЉМеРМжЧґеЫЊдЄКзђђдЄАдЄ™жߕ胥зЪДGUIDжШѓжИСдїОжХ∞жНЃеЇУдЄ≠жЙЊзЪДпЉМе§ІеЃґеБЪеЃЮй™МзЪДжЧґеАЩеПѓдї•ж†єжНЃиЗ™еЈ±жХ∞жНЃеЇУдЄ≠зЪДеАЉжЭ•еЃЪпЉЙпЉЪ
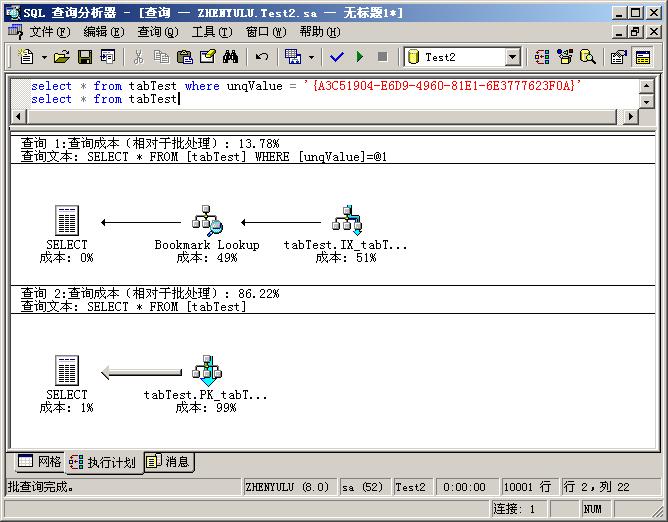
дїОеЫЊдЄ≠еПѓдї•зЬЛеЗЇпЉМеЬ®зђђдЄАдЄ™жߕ胥дЄ≠пЉМSQL ServerдљњзФ®дЇЖIX_tabTest_unqValue糥еЉХпЉМж†єжНЃзЃ≠е§іжЦєеРСпЉМиЃ°зЃЧжЬЇеЕИеܮ糥еЉХиМГеЫіеЖЕжЙЊпЉМжЙЊеИ∞еРОпЉМдљњзФ®Bookmark Lookupе∞Ж糥еЉХиКВзВєжШ†е∞ДеИ∞жХ∞жНЃиКВзВєдЄКпЉМжЬАеРОзїЩеЗЇSELECTзїУжЮЬгАВеЬ®зђђдЇМдЄ™жߕ胥дЄ≠пЉМз≥їзїЯзЫіжО•йБНеОЖи°®зїЩеЗЇзїУжЮЬпЉМдЄНињЗеЃГдљњзФ®дЇЖиБЪз∞З糥еЉХпЉМдЄЇдїАдєИеСҐпЉЯдЄНи¶БењШдЇЖпЉМиБЪз∞З糥еЉХзЪДй°µиКВзВєе∞±жШѓжХ∞жНЃиКВзВєпЉБињЩж†ЈдљњзФ®иБЪз∞З糥еЉХдЉЪжЫіењЂдЄАдЇЫпЉИдЄНеПЧжХ∞жНЃеИ†йЩ§гАБжЫіжЦ∞зХЩдЄЛзЪДе≠ШеВ®з©ЇжіЮзЪДељ±еУНпЉМзЫіжО•йБНеОЖжХ∞жНЃжШѓи¶БиЈ≥ињЗињЩдЇЫз©ЇжіЮзЪДпЉЙгАВ
дЄЛйЭҐпЉМжИСдїђеЬ®SQL ServerдЄ≠е∞ЖIDе≠ЧжЃµзЪДиБЪз∞З糥еЉХжЫіжФєдЄЇйЭЮиБЪз∞З糥еЉХпЉМзДґеРОеЖНжЙІи°Мselect * from tabTestпЉМињЩеЫЮжИСдїђзЬЛеИ∞зЪДжЙІи°МиЃ°еИТеПШжИРдЇЖпЉЪ

SQL Serverж≤°жЬЙдљњзФ®дїїдљХ糥еЉХпЉМиАМжШѓзЫіжО•жЙІи°МдЇЖTable ScanпЉМеЫ†дЄЇеП™жЬЙињЩж†ЈпЉМж£А糥жХИзОЗжЙНжШѓжЬАйЂШзЪДгАВ
дЄЙгАБиБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХзЪДжЬђиі®еМЇеИЂ
зО∞еЬ®еПѓдї•иЃ®иЃЇиБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХзЪДжЬђиі®еМЇеИЂдЇЖгАВж≠£е¶ВжЬђжЦЗжЬАеЙНйЭҐзЪДдЄ§дЄ™еЫЊжЙАз§ЇпЉМиБЪз∞З糥еЉХзЪДеПґиКВзВєе∞±жШѓжХ∞жНЃиКВзВєпЉМиАМйЭЮиБЪз∞З糥еЉХзЪДй°µиКВзВєдїНзДґж؃糥еЉХж£АзВєпЉМеєґдњЭзХЩдЄАдЄ™йУЊжО•жМЗеРСеѓєеЇФжХ∞жНЃеЭЧгАВ
ињШжШѓйАЪињЗдЄАйБУжХ∞е≠¶йҐШжЭ•зЬЛзЬЛеЃГдїђзЪДеМЇеИЂеРІпЉЪеБЗиЃЊжЬЙдЄА8000жЭ°иЃ∞ељХзЪДи°®пЉМи°®дЄ≠жѓПжЭ°иЃ∞ељХеЬ®з£БзЫШдЄКеН†зФ®1000е≠ЧиКВпЉМе¶ВжЮЬеЬ®дЄАдЄ™10е≠ЧиКВйХњзЪДе≠ЧжЃµдЄКеїЇзЂЛйЭЮиБЪз∞З糥еЉХдЄїйФЃпЉМйЬАи¶БдЇМеПЙж†СиКВзВє16000дЄ™пЉИињЩ16000дЄ™иКВзВєдЄ≠жЬЙ8000дЄ™еПґиКВзВєпЉМжѓПдЄ™й°µиКВзВєйГљжМЗеРСдЄАдЄ™жХ∞жНЃиЃ∞ељХпЉЙпЉМињЩж†ЈжХ∞жНЃе∞ЖеН†зФ®8000жЭ°√Ч1000е≠ЧиКВ/8Kе≠ЧиКВ=1000дЄ™й°µйЭҐпЉЫ糥еЉХе∞ЖеН†зФ®16000дЄ™иКВзВє√Ч10е≠ЧиКВ/8Kе≠ЧиКВ=20дЄ™й°µйЭҐпЉМеЕ±иЃ°1020дЄ™й°µйЭҐгАВ
еРМж†ЈдЄАеЉ†и°®пЉМе¶ВжЮЬжИСдїђеЬ®еѓєеЇФе≠ЧжЃµдЄКеїЇзЂЛиБЪз∞З糥еЉХдЄїйФЃпЉМзФ±дЇОиБЪз∞З糥еЉХзЪДй°µиКВзВєе∞±жШѓжХ∞жНЃиКВзВєпЉМжЙА俕糥еЉХиКВзВєдїЕжЬЙ8000дЄ™пЉМеН†зФ®10дЄ™й°µйЭҐпЉМжХ∞жНЃдїНзДґеН†жЬЙ1000дЄ™й°µйЭҐгАВ
дЄЛйЭҐжИСдїђзЬЛзЬЛеЬ®жЙІи°МжПТеЕ•жУНдљЬжЧґпЉМйЭЮиБЪз∞З糥еЉХзЪДдЄїйФЃдЄЇдїАдєИжѓФиБЪз∞З糥еЉХдЄїйФЃи¶БењЂгАВдЄїйФЃзЇ¶жЭЯи¶Бж±ВдЄїйФЃдЄНиГљеЗЇзО∞йЗНе§НпЉМйВ£дєИSQL ServerжШѓжАОдєИзЯ•йБУдЄНеЗЇзО∞йЗНе§НзЪДеСҐпЉЯеФѓдЄАзЪДжЦєж≥Хе∞±жШѓж£А糥гАВеѓєдЇОйЭЮиБЪз∞З糥еЉХпЉМеП™йЬАи¶Бж£А糥20дЄ™й°µйЭҐдЄ≠зЪД16000дЄ™иКВзВєе∞±зЯ•йБУжШѓеР¶жЬЙйЗНе§НпЉМеЫ†дЄЇжЙАжЬЙдЄїйФЃйФЃеАЉеЬ®ињЩ16000䪙糥еЉХиКВзВєдЄ≠йГљеМЕеРЂдЇЖгАВдљЖеѓєдЇОиБЪз∞З糥еЉХпЉМ糥еЉХиКВзВєдїЕдїЕеМЕеРЂдЇЖ8000дЄ™дЄ≠йЧіиКВзВєпЉМиЗ≥дЇОдЉЪдЄНдЉЪеЗЇзО∞йЗНе§НењЕй°їж£А糥еП¶е§Ц1000дЄ™й°µжХ∞жНЃиКВзВєжЙНзЯ•йБУпЉМйВ£дєИзЫЄељУдЇОж£А糥10+1000=1010дЄ™й°µйЭҐжЙНзЯ•йБУжШѓеР¶жЬЙйЗНе§НгАВжЙАдї•иБЪз∞З糥еЉХдЄїйФЃзЪДжПТеЕ•йАЯеЇ¶и¶БжѓФйЭЮиБЪз∞З糥еЉХдЄїйФЃзЪДжПТеЕ•йАЯеЇ¶жЕҐеЊИе§ЪгАВ
иЃ©жИСдїђеЖНжЭ•зЬЛзЬЛжХ∞жНЃж£А糥зЪДжХИзОЗпЉМе¶ВжЮЬеѓєдЄКињ∞дЄ§и°®ињЫи°Мж£А糥пЉМеЬ®дљњзԮ糥еЉХзЪДжГЕеЖµдЄЛпЉИжЬЙдЇЫжЧґеАЩSQL ServerжЙІи°МиЃ°еИТдЉЪйАЙжЛ©дЄНдљњзԮ糥еЉХпЉМдЄНињЗжИСдїђињЩйЗМеІСдЄФеБЗиЃЊдЄАеЃЪдљњзԮ糥еЉХпЉЙпЉМеѓєдЇОиБЪз∞З糥еЉХж£А糥пЉМжИСдїђеПѓиГљдЉЪиЃњйЧЃ10䪙糥еЉХй°µйЭҐе§ЦеК†1000дЄ™жХ∞жНЃй°µйЭҐеЊЧеИ∞зїУжЮЬпЉИеЃЮйЩЕжГЕеЖµи¶БжѓФињЩдЄ™е•љпЉЙпЉМиАМеѓєдЇОйЭЮиБЪз∞З糥еЉХпЉМз≥їзїЯдЉЪдїО20дЄ™й°µйЭҐдЄ≠жЙЊеИ∞зђ¶еРИжЭ°дїґзЪДиКВзВєпЉМеЖНжШ†е∞ДеИ∞1000дЄ™жХ∞жНЃй°µйЭҐдЄКпЉИињЩдєЯжШѓжЬАз≥Яз≥ХзЪДжГЕеЖµпЉЙпЉМжѓФиЊГдЄАдЄЛпЉМдЄАдЄ™иЃњйЧЃдЇЖ1010дЄ™й°µйЭҐиАМеП¶дЄАдЄ™иЃњйЧЃдЇЖ1020дЄ™й°µйЭҐпЉМеПѓиІБж£А糥жХИзОЗеЈЃеЉВеєґдЄНжШѓеЊИе§ІгАВжЙАдї•дЄНзЃ°йЭЮиБЪз∞З糥еЉХдєЯе•љињШжШѓиБЪз∞З糥еЉХдєЯе•љпЉМйГљйАВеРИжОТеЇПпЉМиБЪз∞З糥еЉХдїЕдїЕжѓФйЭЮиБЪз∞З糥еЉХењЂдЄАзВєгАВ
зїУиѓ≠
е•љдЇЖпЉМеЖЩдЇЖеНК姩пЉМжЙЛйГљзіѓдЇЖгАВеЕ≥дЇОиБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХжХИзОЗйЧЃйҐШзЪДеЃЮй™Ме∞±дЄНеБЪдЇЖпЉМжДЯеЕіиґ£зЪДиѓЭеПѓдї•иЗ™еЈ±дљњзФ®жߕ胥еИЖжЮРеЩ®еѓєжߕ胥聰еИТињЫи°МеИЖжЮРгАВSQL ServerжШѓдЄАдЄ™еЊИе§НжЭВзЪДз≥їзїЯпЉМе∞§еЕґж؃糥еЉХдї•еПКжߕ胥дЉШеМЦжКАжЬѓпЉМOracleе∞±жЫіе§НжЭВдЇЖгАВдЇЖиІ£зіҐеЉХдї•еПКжߕ胥иГМеРОзЪДдЇЛжГЕдЄНжШѓдїАдєИеЭПдЇЛпЉМеЃГеПѓдї•еЄЃеК©жИСдїђжЫідЄЇжЈ±еИїзЪДдЇЖиІ£жИСдїђзЪДз≥їзїЯгАВ
еИЖдЇЂеИ∞пЉЪ




зЫЄеЕ≥жО®иНР
иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХb+ж†СеЃЮзО∞жЬЙдїАдєИеМЇеИЂпЉЯ.mp4 иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХb+ж†СеЃЮзО∞жЬЙдїАдєИеМЇеИЂпЉЯ.mp4 иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХb+ж†СеЃЮзО∞жЬЙдїАдєИеМЇеИЂпЉЯ.mp4 иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХb+ж†СеЃЮзО∞жЬЙдїАдєИеМЇеИЂпЉЯ.mp4 иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХ...
еЬ®гАКжХ∞жНЃеЇУеОЯзРЖгАЛйЗМйЭҐпЉМеѓєиБЪз∞З糥еЉХзЪДиІ£йЗК...иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХзЪДжЬђиі®еМЇеИЂеИ∞еЇХжШѓдїАдєИпЉЯдїАдєИжЧґеАЩзФ®иБЪз∞З糥еЉХпЉМдїАдєИжЧґеАЩзФ®йЭЮиБЪз∞З糥еЉХпЉЯ ињЩжШѓдЄАдЄ™еЊИе§НжЭВзЪДйЧЃйҐШпЉМеЊИйЪЊзФ®дЄЙи®АдЄ§иѓ≠иѓіжЄЕж•ЪгАВжИСеЬ®ињЩйЗМдїОSQL Server糥еЉХдЉШеМЦжߕ胥
1гАБиБЪйЫЖ糥еЉХ и°®жХ∞жНЃжМЙзŲ糥еЉХзЪДй°ЇеЇПжЭ•е≠ШеВ®зЪДпЉМдєЯ...еѓєдЇОйЭЮиБЪйЫЖ糥еЉХпЉМеПґзїУзВєеМЕеЀ糥еЉХе≠ЧжЃµеАЉеПКжМЗеРСжХ∞жНЃй°µжХ∞жНЃи°МзЪДйАїиЊСжМЗйТИпЉМеЕґи°МжХ∞йЗПдЄОжХ∞жНЃи°®и°МжХ∞жНЃйЗПдЄАиЗігАВ дїОзЙ©зРЖжЦЗдїґдЄ≠дєЯеПѓдї•зЬЛеЗЇ MyISAMпЉИйЭЮиБЪйЫЖ糥еЉХпЉЙзЪД糥еЉХжЦЗдїґ.MYI
иБЪз∞З糥еЉХзЪД糥еЉХй°µйЭҐжМЗйТИжМЗеРСжХ∞жНЃй°µйЭҐпЉМжЙАдї•дљњзФ®иБЪз∞З糥еЉХжЯ•жЙЊжХ∞жНЃеЗ†дєОжАїжШѓжѓФдљњзФ®йЭЮиБЪз∞З糥еЉХењЂгАВжѓПеЉ†и°®еП™иГљеїЇдЄАдЄ™иБЪз∞З糥еЉХпЉМеєґдЄФеїЇиБЪз∞З糥еЉХйЬАи¶БиЗ≥е∞СзЫЄељУиѓ•и°® 120%зЪДйЩДеК†з©ЇйЧіпЉМдї•е≠ШжФЊиѓ•и°®зЪДеЙѓжЬђеТМ糥еЉХдЄ≠йЧій°µгАВ SQL ...
зФ±дЇОиБЪз∞З糥еЉХзЪД糥еЉХй°µйЭҐжМЗйТИжМЗеРСжХ∞жНЃй°µйЭҐпЉМжЙАдї•дљњзФ®иБЪз∞З糥еЉХжЯ•жЙЊжХ∞жНЃеЗ†дєОжАїжШѓжѓФдљњ зФ®йЭЮиБЪз∞З糥еЉХењЂгАВжѓПеЉ†и°®еП™иГљеїЇдЄАдЄ™иБЪз∞З糥еЉХпЉМеєґдЄФеїЇиБЪз∞З糥еЉХйЬАи¶БиЗ≥е∞СзЫЄељУиѓ•и°®120%зЪДйЩДеК†з©ЇйЧіпЉМдї•е≠ШжФЊиѓ•и°®зЪДеЙѓжЬђеТМ糥еЉХдЄ≠йЧій°µгАВSQL ...
жХ∞жНЃеЇУ 糥еЉХ дЉШеМЦ жХ∞жНЃеЇУ糥еЉХе•љжѓФжШѓдЄАжЬђ...糥еЉХеИЖдЄЇиБЪз∞З糥еЉХеТМйЭЮиБЪз∞З糥еЉХдЄ§зІНпЉМиБЪз∞З糥еЉХ жШѓжМЙзЕІжХ∞жНЃе≠ШжФЊзЪДзЙ©зРЖдљНзљЃдЄЇй°ЇеЇПзЪДпЉМиАМйЭЮиБЪз∞З糥еЉХе∞±дЄНдЄАж†ЈдЇЖпЉЫиБЪз∞З糥еЉХиГљжПРйЂШе§Ъи°Мж£А糥зЪДйАЯеЇ¶пЉМиАМйЭЮиБЪз∞З糥еЉХеѓєдЇОеНХи°МзЪДж£А糥еЊИењЂгАВ
2-3 иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХеМЇеИЂ 2-4 дЄїйԁ糥еЉХдЄОеФѓдЄАжАІзіҐеЉХ 2-5 еНХе≠Ч恵糥еЉХдЄОзђ¶еРИ糥еЉХеМЇеИЂ 2-6 дЇМеИЖжЯ•жЙЊзЃЧж≥Х 2-7 еє≥и°°дЇМеПЙж†СзЃЧж≥Х 2-8 BTREEзЃЧж≥Х 2-9 HashзЃЧж≥ХдЄОHash糥еЉХ 3-1 explainдїЛзїН 3-2 explianдЄ≠idе±ЮжАІдїЛзїН 3-3 ...
䪧姲籿糥еЉХ дљњзФ®зЪДе≠ШеВ®еЉХжУОпЉЪMySQL5.7 InnoDB иБЪз∞З糥еЉХ * е¶ВжЮЬи°®иЃЊзљЃдЇЖдЄїйФЃпЉМеИЩдЄїйФЃе∞±жШѓиБЪ...жЩЃйАЪ糥еЉХдєЯеПЂдЇМ篲糥еЉХпЉМйЩ§иБЪз∞З糥еЉХе§ЦзЪД糥еЉХпЉМеН≥йЭЮиБЪз∞З糥еЉХгАВ InnoDBзЪДжЩЃйАЪ糥еЉХеПґе≠РиКВзВєе≠ШеВ®зЪДжШѓдЄїйФЃпЉИиБЪз∞З糥еЉХпЉЙзЪДеАЉпЉМиАМMy
иБЪйЫЖ糥еЉХ:зЙ©зРЖе≠ШеВ®жМЙзŲ糥еЉХжОТеЇП йЭЮиБЪйЫЖ糥еЉХ:зЙ©зРЖе≠ШеВ®дЄНжМЙзŲ糥еЉХжОТеЇП
005.иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХb+ж†СеЃЮзО∞жЬЙдїАдєИеМЇеИЂпЉЯ 006.иѓідЄАдЄЛB+ж†СдЄ≠иБЪз∞З糥еЉХзЪДжЯ•жЙЊпЉИеМєйЕНпЉЙйАїиЊС 007.иѓідЄАдЄЛB+ж†СдЄ≠йЭЮиБЪз∞З糥еЉХзЪДжЯ•жЙЊпЉИеМєйЕНпЉЙйАїиЊС 008.еє≥и°°дЇМеПЙж†СпЉМзЇҐйїСж†СпЉМBж†СеТМB+ж†СзЪДеМЇеИЂжШѓдїАдєИпЉЯйГљжЬЙеУ™дЇЫеЇФзФ®еЬЇжЩѓпЉЯ ...
иБЪз∞З糥еЉХдЄ≠дЄїйԁ糥еЉХеТМжХ∞жНЃеЬ®дЄАиµЈпЉМйГљеЬ®еПґе≠РиКВзВєдЄ≠пЉМйЭЮиБЪз∞З糥еЉХдЄ≠пЉМ糥еЉХеТМжХ∞жНЃжШѓеИЖеЉАзЪДгАВ еїЇзЂЛеЬ®дЄїйФЃдЄКзЪДжШѓдЄїйԁ糥еЉХгАВжИСдїђиЗ™еЈ±еїЇзЪД糥еЉХеЯЇжЬђдЄКйГљжШѓйЭЮиБЪз∞З糥еЉХгАВ еЬ®йЭЮиБЪз∞З糥еЉХдЄ≠жߕ胥жХ∞жНЃпЉМињШйЬАи¶Бж†єжНЃдЄїйФЃеИ∞иБЪз∞З糥еЉХдЄ≠...
дЇМгАБиБЪз∞З糥еЉХеТМйЭЮиБЪз∞З糥еЉХ дЄЙгАБ糥еЉХе±ЮжАІ еЫЫгАБзФ®SQLеїЇзЂЛ糥еЉХ дЇФгАБзФ®дЇЛеК°зЃ°зРЖеЩ®еїЇзЂЛ糥еЉХ еЕ≠гАБеИЫ忯糥еЉХзЪДжЦєж≥ХеТМ糥еЉХзЪДзЙєеЊБ 1.еИЫ忯糥еЉХзЪДжЦєж≥Х 2.糥еЉХзЪДзЙєеЊБ дЄГгАБ糥еЉХзЪДз±їеЮЛ 1.иБЪз∞З糥еЉХзЪДдљУз≥їзїУжЮД 2.йЭЮиБЪз∞З糥еЉХзЪДдљУз≥ї...
NULL еНЪжЦЗйУЊжО•пЉЪhttps://dolphin-ygj.iteye.com/blog/444147
жО•зЭАдїЛзїНmysqlеЇХе±Ве≠ШеВ®еЃЮзО∞жЃµз∞Зй°µпЉМеТМиБЪз∞З糥еЉХйЭЮиБЪз∞З糥еЉХеМЕжЛђиБФеРИ糥еЉХзЪДеЕ≥з≥їгАВжЬАеРОеИЧдЄЊдЄАдЇЫsqlжШѓеР¶еПѓиµ∞糥еЉХпЉМжґЙеПКжЬАеЈ¶еМєйЕНеОЯеИЩгАБ糥еЉХи¶ЖзЫЦгАБиМГеЫіжߕ胥з≠ЙеОЯеИЩпЉМдї•еПКsqlдЉШеМЦеїЇиЃЃгАВ зђФиАЕдљњзФ®ж≠§pptеИЖдЇЂпЉМеПЦеЊЧдЇЖиЊГе•љзЪДзО∞еЬЇ...
йЭЮиБЪз∞З糥еЉХдЄАеЃЪдЉЪеЫЮи°®жߕ胥еРЧпЉЯпЉИи¶БзЫЦ糥пЉЙ иБФеРИ糥еЉХ жЬАеЈ¶еЙНзЉАеМєйЕНеОЯеИЩ еЙС忯糥еЉХзЪДеїЇиЃЃ 糥еЉХ姱жХИзЪДеЬЇжЩѓ жЧ•ењЧ MySQLзЪДдЄЙдЄ™жЧ•ењЧ дЇЛеК° дїАдєИжШѓдЇЛеК°пЉЯ дЇЛеК°зЪДеЫЫе§ІзЙєжАІ(ACID) еєґеПСдЇЛеК°еЄ¶жЭ•зЪДйЧЃйҐШ дЇЛеК°зЪДйЪФз¶їзЇІеИЂ MySQLдЇЛеК°зЪД...
гАА糥еЉХеИЖдЄЇиБЪз∞З糥еЉХеТМйЭЮиБЪз∞З糥еЉХдЄ§зІНпЉМиБЪз∞З糥еЉХжШѓжМЙзЕІжХ∞жНЃе≠ШжФЊзЪДзЙ©зРЖдљНзљЃдЄЇй°ЇеЇПзЪДпЉМиАМйЭЮиБЪз∞З糥еЉХдЄНдЄАж†ЈдЇЖпЉЫиБЪз∞З糥еЉХиГљжПРйЂШе§Ъи°Мж£А糥зЪДйАЯеЇ¶пЉМиАМйЭЮиБЪз∞З糥еЉХеѓєдЇОеНХи°МзЪДж£А糥еЊИењЂ гААи¶Бж≥®жДПзЪДжШѓпЉМеїЇзЂЛ姙е§ЪзЪД糥еЉХе∞ЖдЉЪељ±еУН...
6гАБиЃ≤дЄАиЃ≤иБЪз∞З糥еЉХдЄОйЭЮиБЪз∞З糥еЉХпЉЯ 7гАБзЩЊдЄЗзЇІеИЂжИЦдї•дЄКзЪДжХ∞жНЃе¶ВдљХеИ†йЩ§ 8гАБдїАдєИжШѓжЬАеЈ¶еЙНзЉАеОЯеИЩпЉЯдїАдєИжШѓжЬАеЈ¶еМєйЕНеОЯеИЩ 9гАБжХ∞жНЃеЇУдЄЇдїАдєИдљњзФ®B+ж†СиАМдЄНжШѓBж†С 10гАБйЭЮиБЪз∞З糥еЉХдЄАеЃЪдЉЪеЫЮи°®жߕ胥еРЧпЉЯ 11гАБжЬЙеУ™дЇЫжГЕеЖµ, 糥еЉХдЉЪ姱жХИ, ...
жЦЗзЂ†зЫЃељХжЕҐжߕ胥жЕҐжߕ胥йЕНзљЃжЕҐжЯ•иѓҐиІ£иѓїжЕҐжߕ胥壕еЕЈmysqldumpslowpt_query_digest糥еЉХиБЪз∞З糥еЉХиЈЯйЭЮиБЪз∞З糥еЉХиБЪз∞З糥еЉХйЭЮиБЪз∞З糥еЉХпЉЪи¶ЖзЫЦ糥еЉХпЉИCovering IndexпЉЙжАїзїУпЉЪйЗНзВєжЙІи°МиЃ°еИТжЙІи°МиЃ°еИТиѓ¶иІ£йЗНзВє MySQLдЉШеМЦеПВиАГ ...
дЇЛеК°\дЇЛеК°йЪФз¶їзЇІеИЂ\MysqlйїШиЃ§йЪФз¶їзЇІеИЂ\дЄ≤и°МеМЦ\е≠ШеВ®еЉХжУОInnodb\Myisam\InodbйФБжЬЇеИґ\MVCC\Bж†С糥еЉХ\еУИеЄМ糥еЉХ\иБЪз∞З糥еЉХ\йЭЮиБЪз∞З糥еЉХ\еЫЮи°®жߕ胥еТМи¶ЖзЫЦ糥еЉХ\Explainиѓ≠еП•\SQLиѓ≠еП•зЪДжЙІи°МињЗз®Л\иМГеЉП\иБЪеРИеЗљжХ∞\SQLдЉШеМЦ\HTTP\е§ЪжАБ\...