ن¸»وœ؛çژ¯ه¢ƒï¼ڑUbuntu 13.04
Python版وœ¬ï¼ڑ2.7.4
——————————————————————————————————————————————————-
و‰€è°“网络爬虫,ه°±وک¯ن¸€ن¸ھهœ¨ç½‘ن¸ٹهˆ°ه¤„وˆ–ه®ڑهگ‘وٹ“هڈ–و•°وچ®çڑ„程ه؛ڈ,ه½“然,è؟™ç§چ说و³•ن¸چه¤ںن¸“ن¸ڑ,و›´ن¸“ن¸ڑçڑ„وڈڈè؟°ه°±وک¯ï¼Œوٹ“هڈ–特ه®ڑ网站网é،µçڑ„HTMLو•°وچ®م€‚ن¸چè؟‡ç”±ن؛ژن¸€ن¸ھ网站çڑ„网é،µه¾ˆه¤ڑ,而وˆ‘ن»¬هڈˆن¸چهڈ¯èƒ½ن؛‹ه…ˆçں¥éپ“و‰€وœ‰ç½‘é،µçڑ„URLهœ°ه€ï¼Œو‰€ن»¥ï¼Œه¦‚ن½•ن؟è¯پوˆ‘ن»¬وٹ“هڈ–هˆ°ن؛†ç½‘ç«™çڑ„و‰€وœ‰HTMLé،µé¢ه°±وک¯ن¸€ن¸ھوœ‰ه¾…考究çڑ„é—®é¢کن؛†م€‚
ن¸€èˆ¬çڑ„و–¹و³•وک¯ï¼Œه®ڑن¹‰ن¸€ن¸ھه…¥هڈ£é،µé¢ï¼Œç„¶هگژن¸€èˆ¬ن¸€ن¸ھé،µé¢ن¼ڑوœ‰ه…¶ن»–é،µé¢çڑ„URL,ن؛ژوک¯ن»ژه½“ه‰چé،µé¢èژ·هڈ–هˆ°è؟™ن؛›URLهٹ ه…¥هˆ°çˆ¬è™«çڑ„وٹ“هڈ–éکںهˆ—ن¸ï¼Œç„¶هگژè؟›ه…¥هˆ°و–°و–°é،µé¢هگژه†چ递ه½’çڑ„è؟›è،Œن¸ٹè؟°çڑ„و“چن½œï¼Œه…¶ه®è¯´و¥ه°±è·ںو·±ه؛¦éپچهژ†وˆ–ه¹؟ه؛¦éپچهژ†ن¸€و ·م€‚
ن¸ٹé¢ن»‹ç»چçڑ„هڈھوک¯çˆ¬è™«çڑ„ن¸€ن؛›و¦‚ه؟µè€Œéوگœç´¢ه¼•و“ژ,ه®é™…ن¸ٹوگœç´¢ه¼•و“ژçڑ„è¯ه…¶ç³»ç»ںوک¯ç›¸ه½“ه¤چو‚çڑ„,爬虫هڈھوک¯وگœç´¢ه¼•و“ژçڑ„ن¸€ن¸ھهگç³»ç»ں而ه·²م€‚
Pythonه¼€و؛گçڑ„爬虫و،†و¶Scrapyوک¯ن¸€ن¸ھه؟«é€ں,é«که±‚و¬،çڑ„ه±ڈه¹•وٹ“هڈ–ه’Œwebوٹ“هڈ–و،†و¶ï¼Œç”¨ن؛ژوٹ“هڈ–web站点ه¹¶ن»ژé،µé¢ن¸وڈگهڈ–结و„هŒ–çڑ„و•°وچ®م€‚Scrapy用途ه¹؟و³›ï¼Œهڈ¯ن»¥ç”¨ن؛ژو•°وچ®وŒ–وژکم€پ监وµ‹ه’Œè‡ھهٹ¨هŒ–وµ‹è¯•م€‚Scrapyهگ¸ه¼•ن؛؛çڑ„هœ°و–¹هœ¨ن؛ژه®ƒوک¯ن¸€ن¸ھو،†و¶ï¼Œن»»ن½•ن؛؛都هڈ¯ن»¥و ¹وچ®éœ€و±‚و–¹ن¾؟çڑ„ن؟®و”¹م€‚ه®ƒن¹ںوڈگن¾›ن؛†ه¤ڑç§چç±»ه‹çˆ¬è™«çڑ„هں؛类,ه¦‚BaseSpiderم€پsitemap爬虫ç‰ï¼Œوœ€و–°ç‰ˆوœ¬هڈˆوڈگن¾›ن؛†web2.0爬虫çڑ„و”¯وŒپم€‚
ن¸€م€پو¦‚è؟°
Scrapyوک¯ن¸€ن¸ھ用 Python ه†™çڑ„ Crawler Framework ,简هچ•è½»ه·§ï¼Œه¹¶ن¸”éه¸¸و–¹ن¾؟,ه¹¶ن¸”ه®ک网ن¸ٹ说ه·²ç»ڈهœ¨ه®é™…ç”ںن؛§ن¸هœ¨ن½؟用ن؛†ï¼Œن¸چè؟‡çژ°هœ¨è؟کو²،وœ‰ Release 版وœ¬ï¼Œهڈ¯ن»¥ç›´وژ¥ن½؟用ن»–ن»¬çڑ„ Mercurial ن»“ه؛“里وٹ“هڈ–و؛گç پè؟›è،Œه®‰è£…م€‚
Scrapy ن½؟用 Twisted è؟™ن¸ھه¼‚و¥ç½‘络ه؛“و¥ه¤„çگ†ç½‘络é€ڑ讯,و¶و„و¸…و™°ï¼Œه¹¶ن¸”هŒ…هگ«ن؛†هگ„ç§چن¸é—´ن»¶وژ¥هڈ£ï¼Œهڈ¯ن»¥çپµو´»çڑ„ه®Œوˆگهگ„ç§چ需و±‚م€‚
Scrapyو•´ن½“و¶و„ه¦‚ن¸‹ه›¾و‰€ç¤؛,ه…¶ن¸هŒ…هگ«ن؛†ه®ƒçڑ„ن¸»è¦پ组ن»¶هڈٹç³»ç»ںçڑ„و•°وچ®ه¤„çگ†وµپ程(ç»؟色ç®ه¤´و‰€ç¤؛)م€‚ن¸‹é¢ه°±و¥ن¸€ن¸ھن¸ھ解é‡ٹو¯ڈن¸ھ组ن»¶çڑ„ن½œç”¨هڈٹو•°وچ®çڑ„ه¤„çگ†è؟‡ç¨‹م€‚
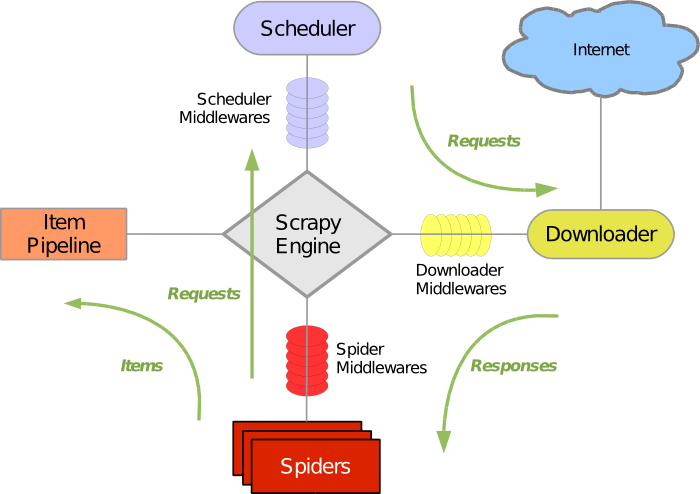
ç»؟ç؛؟وک¯و•°وچ®وµپهگ‘,首ه…ˆن»ژهˆه§‹ URL ه¼€ه§‹ï¼ŒScheduler ن¼ڑه°†ه…¶ن؛¤ç»™ Downloader è؟›è،Œن¸‹è½½ï¼Œن¸‹è½½ن¹‹هگژن¼ڑن؛¤ç»™ Spider è؟›è،Œهˆ†وگ,Spider هˆ†وگه‡؛و¥çڑ„结وœوœ‰ن¸¤ç§چï¼ڑن¸€ç§چوک¯éœ€è¦پè؟›ن¸€و¥وٹ“هڈ–çڑ„链وژ¥ï¼Œن¾‹ه¦‚ن¹‹ه‰چهˆ†وگçڑ„“ن¸‹ن¸€é،µâ€çڑ„链وژ¥ï¼Œè؟™ن؛›ن¸œè¥؟ن¼ڑ被ن¼ ه› Scheduler ï¼›هڈ¦ن¸€ç§چوک¯éœ€è¦پن؟هکçڑ„و•°وچ®ï¼Œه®ƒن»¬هˆ™è¢«é€پهˆ° Item Pipeline 那里,那وک¯ه¯¹و•°وچ®è؟›è،Œهگژوœںه¤„çگ†ï¼ˆè¯¦ç»†هˆ†وگم€پè؟‡و»¤م€پهکه‚¨ç‰ï¼‰çڑ„هœ°و–¹م€‚هڈ¦ه¤–,هœ¨و•°وچ®وµپهٹ¨çڑ„é€ڑéپ“里è؟کهڈ¯ن»¥ه®‰è£…هگ„ç§چن¸é—´ن»¶ï¼Œè؟›è،Œه؟…è¦پçڑ„ه¤„çگ†م€‚
ن؛Œم€پ组ن»¶
1م€پScrapy Engine(Scrapyه¼•و“ژ)
Scrapyه¼•و“ژوک¯ç”¨و¥وژ§هˆ¶و•´ن¸ھç³»ç»ںçڑ„و•°وچ®ه¤„çگ†وµپ程,ه¹¶è؟›è،Œن؛‹هٹ،ه¤„çگ†çڑ„触هڈ‘م€‚و›´ه¤ڑçڑ„详细ه†…ه®¹هڈ¯ن»¥çœ‹ن¸‹é¢çڑ„و•°وچ®ه¤„çگ†وµپ程م€‚
2م€پScheduler(调ه؛¦ï¼‰
è°ƒه؛¦ç¨‹ه؛ڈن»ژScrapyه¼•و“ژوژ¥هڈ—请و±‚ه¹¶وژ’ه؛ڈهˆ—ه…¥éکںهˆ—,ه¹¶هœ¨Scrapyه¼•و“ژهڈ‘ه‡؛请و±‚هگژè؟”è؟کç»™ن»–ن»¬م€‚
3م€پDownloader(ن¸‹è½½ه™¨ï¼‰
ن¸‹è½½ه™¨çڑ„ن¸»è¦پèپŒè´£وک¯وٹ“هڈ–网é،µه¹¶ه°†ç½‘é،µه†…ه®¹è؟”è؟کç»™èœکè››( Spiders)م€‚
4م€پSpiders(èœک蛛)
èœکè››وک¯وœ‰Scrapy用وˆ·è‡ھه·±ه®ڑن¹‰ç”¨و¥è§£وگ网é،µه¹¶وٹ“هڈ–هˆ¶ه®ڑURLè؟”ه›çڑ„ه†…ه®¹çڑ„类,و¯ڈن¸ھèœک蛛都能ه¤„çگ†ن¸€ن¸ھهںںهگچوˆ–ن¸€ç»„هںںهگچم€‚وچ¢هڈ¥è¯è¯´ه°±وک¯ç”¨و¥ه®ڑن¹‰ç‰¹ه®ڑ网站çڑ„وٹ“هڈ–ه’Œè§£وگ规هˆ™م€‚
èœکè››çڑ„و•´ن¸ھوٹ“هڈ–وµپ程(ه‘¨وœں)وک¯è؟™و ·çڑ„ï¼ڑ
- 首ه…ˆèژ·هڈ–第ن¸€ن¸ھURLçڑ„هˆه§‹è¯·و±‚,ه½“请و±‚è؟”ه›هگژè°ƒهڈ–ن¸€ن¸ھه›è°ƒه‡½و•°م€‚第ن¸€ن¸ھ请و±‚وک¯é€ڑè؟‡è°ƒç”¨start_requests()و–¹و³•م€‚该و–¹و³•é»ک认ن»ژstart_urlsن¸çڑ„Urlن¸ç”ںوˆگ请و±‚,ه¹¶و‰§è،Œè§£وگو¥è°ƒç”¨ه›è°ƒه‡½و•°م€‚
- هœ¨ه›è°ƒه‡½و•°ن¸ï¼Œن½ هڈ¯ن»¥è§£وگ网é،µه“چه؛”ه¹¶è؟”ه›é،¹ç›®ه¯¹è±،ه’Œè¯·و±‚ه¯¹è±،وˆ–ن¸¤è€…çڑ„è؟ن»£م€‚è؟™ن؛›è¯·و±‚ن¹ںه°†هŒ…هگ«ن¸€ن¸ھه›è°ƒï¼Œç„¶هگژ被Scrapyن¸‹è½½ï¼Œç„¶هگژوœ‰وŒ‡ه®ڑçڑ„ه›è°ƒه¤„çگ†م€‚
- هœ¨ه›è°ƒه‡½و•°ن¸ï¼Œن½ 解وگ网站çڑ„ه†…ه®¹ï¼ŒهگŒç¨‹ن½؟用çڑ„وک¯Xpath选و‹©ه™¨ï¼ˆن½†وک¯ن½ ن¹ںهڈ¯ن»¥ن½؟用BeautifuSoup, lxmlوˆ–ه…¶ن»–ن»»ن½•ن½ ه–œو¬¢çڑ„程ه؛ڈ),ه¹¶ç”ںوˆگ解وگçڑ„و•°وچ®é،¹م€‚
- وœ€هگژ,ن»ژèœکè››è؟”ه›çڑ„é،¹ç›®é€ڑه¸¸ن¼ڑè؟›é©»هˆ°é،¹ç›®ç®،éپ“م€‚
5م€پItem Pipeline(é،¹ç›®ç®،éپ“)
é،¹ç›®ç®،éپ“çڑ„ن¸»è¦پè´£ن»»وک¯è´ںè´£ه¤„çگ†وœ‰èœکè››ن»ژ网é،µن¸وٹ½هڈ–çڑ„é،¹ç›®ï¼Œن»–çڑ„ن¸»è¦پن»»هٹ،وک¯و¸…و™°م€پéھŒè¯په’Œهکه‚¨و•°وچ®م€‚ه½“é،µé¢è¢«èœک蛛解وگهگژ,ه°†è¢«هڈ‘é€پهˆ°é،¹ç›®ç®،éپ“,ه¹¶ç»ڈè؟‡ه‡ ن¸ھ特ه®ڑçڑ„و¬،ه؛ڈه¤„çگ†و•°وچ®م€‚و¯ڈن¸ھé،¹ç›®ç®،éپ“çڑ„组ن»¶éƒ½وک¯وœ‰ن¸€ن¸ھ简هچ•çڑ„و–¹و³•ç»„وˆگçڑ„Pythonç±»م€‚ن»–ن»¬èژ·هڈ–ن؛†é،¹ç›®ه¹¶و‰§è،Œن»–ن»¬çڑ„و–¹و³•ï¼ŒهگŒو—¶ن»–ن»¬è؟ک需è¦پç،®ه®ڑçڑ„وک¯وک¯هگ¦éœ€è¦پهœ¨é،¹ç›®ç®،éپ“ن¸ç»§ç»و‰§è،Œن¸‹ن¸€و¥وˆ–وک¯ç›´وژ¥ن¸¢ه¼ƒوژ‰ن¸چه¤„çگ†م€‚
é،¹ç›®ç®،éپ“é€ڑه¸¸و‰§è،Œçڑ„è؟‡ç¨‹وœ‰ï¼ڑ
- و¸…و´—HTMLو•°وچ®
- éھŒè¯پ解وگهˆ°çڑ„و•°وچ®ï¼ˆو£€وں¥é،¹ç›®وک¯هگ¦هŒ…هگ«ه؟…è¦پçڑ„ه—و®µï¼‰
- و£€وں¥وک¯هگ¦وک¯é‡چه¤چو•°وچ®ï¼ˆه¦‚وœé‡چه¤چه°±هˆ 除)
- ه°†è§£وگهˆ°çڑ„و•°وچ®هکه‚¨هˆ°و•°وچ®ه؛“ن¸
6م€پDownloader middlewares(ن¸‹è½½ه™¨ن¸é—´ن»¶ï¼‰
ن¸‹è½½ن¸é—´ن»¶وک¯ن½چن؛ژScrapyه¼•و“ژه’Œن¸‹è½½ه™¨ن¹‹é—´çڑ„é’©هگو،†و¶ï¼Œن¸»è¦پوک¯ه¤„çگ†Scrapyه¼•و“ژن¸ژن¸‹è½½ه™¨ن¹‹é—´çڑ„请و±‚هڈٹه“چه؛”م€‚ه®ƒوڈگن¾›ن؛†ن¸€ن¸ھè‡ھه®ڑن¹‰çڑ„ن»£ç پçڑ„و–¹ه¼ڈو¥و‹“ه±•Scrapyçڑ„هٹں能م€‚ن¸‹è½½ن¸é—´ه™¨وک¯ن¸€ن¸ھه¤„çگ†è¯·و±‚ه’Œه“چه؛”çڑ„é’©هگو،†و¶م€‚ن»–وک¯è½»é‡ڈç؛§çڑ„,ه¯¹Scrapyه°½ن؛«ه…¨ه±€وژ§هˆ¶çڑ„ه؛•ه±‚çڑ„ç³»ç»ںم€‚
7م€پSpider middlewares(èœکè››ن¸é—´ن»¶ï¼‰
èœکè››ن¸é—´ن»¶وک¯ن»‹ن؛ژScrapyه¼•و“ژه’Œèœکè››ن¹‹é—´çڑ„é’©هگو،†و¶ï¼Œن¸»è¦په·¥ن½œوک¯ه¤„çگ†èœکè››çڑ„ه“چه؛”输ه…¥ه’Œè¯·و±‚输ه‡؛م€‚ه®ƒوڈگن¾›ن¸€ن¸ھè‡ھه®ڑن¹‰ن»£ç پçڑ„و–¹ه¼ڈو¥و‹“ه±•Scrapyçڑ„هٹں能م€‚è››ن¸é—´ن»¶وک¯ن¸€ن¸ھوŒ‚وژ¥هˆ°Scrapyçڑ„èœکè››ه¤„çگ†وœ؛هˆ¶çڑ„و،†و¶ï¼Œن½ هڈ¯ن»¥وڈ’ه…¥è‡ھه®ڑن¹‰çڑ„ن»£ç پو¥ه¤„çگ†هڈ‘é€پç»™èœکè››çڑ„请و±‚ه’Œè؟”ه›èœکè››èژ·هڈ–çڑ„ه“چه؛”ه†…ه®¹ه’Œé،¹ç›®م€‚
8م€پScheduler middlewares(调ه؛¦ن¸é—´ن»¶ï¼‰
è°ƒه؛¦ن¸é—´ن»¶وک¯ن»‹ن؛ژScrapyه¼•و“ژه’Œè°ƒه؛¦ن¹‹é—´çڑ„ن¸é—´ن»¶ï¼Œن¸»è¦په·¥ن½œوک¯ه¤„ن»ژScrapyه¼•و“ژهڈ‘é€پهˆ°è°ƒه؛¦çڑ„请و±‚ه’Œه“چه؛”م€‚ن»–وڈگن¾›ن؛†ن¸€ن¸ھè‡ھه®ڑن¹‰çڑ„ن»£ç پو¥و‹“ه±•Scrapyçڑ„هٹں能م€‚
ن¸‰م€پو•°وچ®ه¤„çگ†وµپ程
Scrapyçڑ„و•´ن¸ھو•°وچ®ه¤„çگ†وµپ程وœ‰Scrapyه¼•و“ژè؟›è،Œوژ§هˆ¶ï¼Œه…¶ن¸»è¦پçڑ„è؟گè،Œو–¹ه¼ڈن¸؛ï¼ڑ
- ه¼•و“ژو‰“ه¼€ن¸€ن¸ھهںںهگچ,و—¶èœکè››ه¤„çگ†è؟™ن¸ھهںںهگچ,ه¹¶è®©èœکè››èژ·هڈ–第ن¸€ن¸ھ爬هڈ–çڑ„URLم€‚
- ه¼•و“ژن»ژèœک蛛那èژ·هڈ–第ن¸€ن¸ھ需è¦پ爬هڈ–çڑ„URL,然هگژن½œن¸؛请و±‚هœ¨è°ƒه؛¦ن¸è؟›è،Œè°ƒه؛¦م€‚
- ه¼•و“ژن»ژè°ƒه؛¦é‚£èژ·هڈ–وژ¥ن¸‹و¥è؟›è،Œçˆ¬هڈ–çڑ„é،µé¢م€‚
- è°ƒه؛¦ه°†ن¸‹ن¸€ن¸ھ爬هڈ–çڑ„URLè؟”ه›ç»™ه¼•و“ژ,ه¼•و“ژه°†ن»–ن»¬é€ڑè؟‡ن¸‹è½½ن¸é—´ن»¶هڈ‘é€پهˆ°ن¸‹è½½ه™¨م€‚
- ه½“网é،µè¢«ن¸‹è½½ه™¨ن¸‹è½½ه®Œوˆگن»¥هگژ,ه“چه؛”ه†…ه®¹é€ڑè؟‡ن¸‹è½½ن¸é—´ن»¶è¢«هڈ‘é€پهˆ°ه¼•و“ژم€‚
- ه¼•و“ژو”¶هˆ°ن¸‹è½½ه™¨çڑ„ه“چه؛”ه¹¶ه°†ه®ƒé€ڑè؟‡èœکè››ن¸é—´ن»¶هڈ‘é€پهˆ°èœکè››è؟›è،Œه¤„çگ†م€‚
- èœکè››ه¤„çگ†ه“چه؛”ه¹¶è؟”ه›çˆ¬هڈ–هˆ°çڑ„é،¹ç›®ï¼Œç„¶هگژç»™ه¼•و“ژهڈ‘é€پو–°çڑ„请و±‚م€‚
- ه¼•و“ژه°†وٹ“هڈ–هˆ°çڑ„é،¹ç›®é،¹ç›®ç®،éپ“,ه¹¶هگ‘è°ƒه؛¦هڈ‘é€پ请و±‚م€‚
- ç³»ç»ںé‡چه¤چ第ن؛Œéƒ¨هگژé¢çڑ„و“چن½œï¼Œç›´هˆ°è°ƒه؛¦ن¸و²،وœ‰è¯·و±‚,然هگژو–ه¼€ه¼•و“ژن¸ژهںںن¹‹é—´çڑ„èپ”ç³»م€‚
ه››م€پ驱هٹ¨ه™¨
Scrapyوک¯ç”±Twistedه†™çڑ„ن¸€ن¸ھهڈ—و¬¢è؟ژçڑ„Pythonن؛‹ن»¶é©±هٹ¨ç½‘络و،†و¶ï¼Œه®ƒن½؟用çڑ„وک¯éه µه،çڑ„ه¼‚و¥ه¤„çگ†م€‚ه¦‚وœè¦پèژ·ه¾—و›´ه¤ڑه…³ن؛ژه¼‚و¥ç¼–程ه’ŒTwistedçڑ„ن؟،وپ¯ï¼Œè¯·هڈ‚考ن¸‹é¢ن¸¤و،链وژ¥م€‚
هڈ‚考و–‡çŒ®ï¼ڑhttp://doc.scrapy.org/topics/architecture.html
————————————————————————————————————————————————-
ن»¥ن¸ٹه†…ه®¹è½¬è½½è‡ھhttp://www.tuicool.com/articles/fiyIbq
ن¹ںهڈ¯ن»¥هڈ‚考ه®کو–¹çڑ„و–‡و،£م€‚
ن¸‹é¢çڑ„ه®ن¾‹ه®çژ°çڑ„وک¯çˆ¬هڈ–وœ¬هچڑه®¢çڑ„و‰€وœ‰و–‡ç« م€‚
ه®ڑهˆ¶çڑ„爬虫ن»£ç پï¼ڑmy_spider.py
04 |
fromscrapy.spiderimportBaseSpider
|
05 |
fromscrapy.selectorimportHtmlXPathSelector
|
07 |
frommymodules.itemsimportWebsite
|
09 |
classMy_Spider(BaseSpider):
|
11 |
allowed_domains=["yanming8.cn"]
|
16 |
defparse(self, response):
|
17 |
hxs=HtmlXPathSelector(response)
|
18 |
blogs_url=hxs.select('//h2/a/@href').extract()
|
20 |
items.extend([self.make_requests_from_url(url).replace(callback=self.parse_post)
|
23 |
pages=hxs.select('//div[@class="loop-nav-previous grid_5 alpha"]/a[not(@title)]/@href').extract()
|
25 |
items.append(self.make_requests_from_url(next_page))
|
29 |
defparse_post(self, response):
|
31 |
hxs=HtmlXPathSelector(response)
|
34 |
item['url']=unicode(response.url)
|
35 |
item['name']=hxs.select('//h1[@class="entry-title entry-title-single"]/text()').extract()
|
36 |
item['description']=response.body_as_unicode()
|
37 |
printresponse.url,item['name']
|
ن»£ç پن¸parseه‡½و•°وک¯ç”¨ن؛ژèژ·هڈ–و–‡ç« هˆ—è،¨çڑ„,ه¹¶ه°†و¯ڈن¸€é،µçڑ„و–‡ç« هœ°ه€هٹ ه…¥listهˆ—è،¨ه¹¶è؟”ه›ï¼Œè¯¥ه‡½و•°وک¯é»ک认çڑ„ه›è°ƒه‡½و•°م€‚
ن»£ç پن¸parse_postه‡½و•°وک¯ç”¨ن؛ژèژ·هڈ–و¯ڈ篇و–‡ç« çڑ„ه…·ن½“ه†…ه®¹م€‚
然هگژن¼ڑè؟”ه›ç»™pipelineè؟›è،Œه¤„çگ†ï¼Œهœ¨è؟™é‡Œهڈ¯ن»¥è؟›è،Œç´¢ه¼•ه†…ه®¹çڑ„و–‡ن»¶وˆ–者و•°وچ®ه؛“هکه‚¨م€‚
هˆ†ن؛«هˆ°ï¼ڑ




相ه…³وژ¨èچگ
Scrapyن¸€ن¸ھه¼€و؛گه’Œهچڈن½œçڑ„و،†و¶ï¼Œه…¶وœ€هˆوک¯ن¸؛ن؛†é،µé¢وٹ“هڈ– (و›´ç،®هˆ‡و¥è¯´, 网络وٹ“هڈ– )و‰€è®¾è®،çڑ„,ن½؟用ه®ƒهڈ¯ن»¥ن»¥ه؟«é€ںم€پ简هچ•م€پهڈ¯و‰©ه±•çڑ„و–¹ه¼ڈن»ژ网站ن¸وڈگهڈ–و‰€éœ€çڑ„و•°وچ®م€‚ن½†ç›®ه‰چScrapyçڑ„用途هچپهˆ†ه¹؟و³›ï¼Œهڈ¯ç”¨ن؛ژه¦‚و•°وچ®وŒ–وژکم€پ监وµ‹ه’Œè‡ھهٹ¨هŒ–...
ن½؟用Charles,mitmdump,Appiumç‰ه·¥ه…·ه®çژ°App爬هڈ–çڑ„و–¹و³•ï¼Œç´§وژ¥ç€ن»‹ç»چن؛†pyspiderو،†و¶ه’ŒScrapyو،†و¶çڑ„ن½؟用,ن»¥هڈٹهˆ†ه¸ƒه¼ڈ爬虫çڑ„çں¥è¯†ï¼Œوœ€هگژن»‹ç»چن؛†Bloom Filterو•ˆçژ‡ن¼کهŒ–,Dockerه’ŒScrapyd爬虫部署,Ger
feapderوک¯ن¸€ç§چ简هچ•ï¼Œه؟«é€ں,轻é‡ڈç؛§çڑ„爬虫و،†و¶م€‚èµ·هگچو؛گن؛ژfast,easy,air,pro,spiderçڑ„缩ه†™ï¼Œن»¥ه¼€هڈ‘ه؟«é€ں,وٹ“هڈ–ه؟«é€ں,ن½؟用简هچ•ï¼Œهٹں能ه¼؛ه¤§ن¸؛ن¸€ن½“,هژ†و—¶4ه¹´ه€¾ه؟ƒو‰“é€ م€‚و”¯وŒپè½»é‡ڈ爬虫,هˆ†ه¸ƒçˆ¬è™«ï¼Œه¹¶هˆ—爬虫,爬虫集وˆگ,ن»¥هڈٹ...
èœکè›› ه¦ن¹ ن¸çڑ„ه†™çڑ„ن¸€ن؛›çˆ¬è™«ن»£ç پ,هŒ…و‹¬و·که®ï¼Œه¤§ه‹و–°é—»ç½‘站,ن¸€ن؛›ه®éھŒو•°وچ®ç½‘ç«™ç‰ï¼Œو‰€وœ‰çˆ¬è™«هں؛ن؛ژpython3,部هˆ†çˆ¬è™«هں؛ن؛ژscrapyو،†و¶م€‚و·که®ï¼ڑو·که®çˆ¬è™«cma_data_spiderï¼ڑن¸ه›½و°”è±،و•°وچ®ç½‘爬虫
scrapyوک¯ن¸€ن¸ھPython爬虫و،†و¶ï¼Œçˆ¬هڈ–و•ˆçژ‡وپé«ک,ه…·وœ‰é«که؛¦ه®ڑهˆ¶و€§ï¼Œن½†وک¯ن¸چو”¯وŒپهˆ†ه¸ƒه¼ڈم€‚而scrapy-redisن¸€ه¥—هں؛ن؛ژredisو•°وچ®ه؛“م€پè؟گè،Œهœ¨scrapyو،†و¶ن¹‹ن¸ٹçڑ„组ن»¶ï¼Œهڈ¯ن»¥è®©scrapyو”¯وŒپهˆ†ه¸ƒه¼ڈç–略,Slaver端ه…±ن؛«Master端redisو•°وچ®ه؛“里...
leetcodeèچ资 ...爬虫(scrapySpiderو–‡ن»¶ه¤¹ï¼‰ï¼ڑ 网وک“ï¼ڑ ه‡¤ه‡°ç½‘ï¼ڑ FTن¸و–‡ç½‘ï¼ڑ 第ن¸€è´¢ç»ڈï¼ڑ ه¤‡و³¨ ç»ںن¸€و—¶é—´و ¼ه¼ڈ: YY-NN-DD HH:MM و¥و؛گï¼ڑ 第ن¸€è´¢ç»ڈ: yicai FTن¸و–‡ç½‘: ftchinese ه‡¤ه‡°ç½‘: ifeng 网وک“è´¢ç»ڈ: wangyi
moear-spider-zhihudailyMoEarçڑ„爬虫وڈ’ن»¶ï¼Œç”¨ن»¥وڈگن¾›ه¯¹çں¥ن¹ژو—¥وٹ¥çڑ„و–‡ç« 爬هڈ–ن»¥هڈٹو–‡ç« و ¼ه¼ڈهŒ–ç‰هٹں能BadgeGitHubو–‡و،£PyPiه…¶ن»–Licenseوœ¬é،¹ç›®é‡‡ç”¨ هچڈè®®ه¼€و؛گهڈ‘ه¸ƒï¼Œè¯·و‚¨هœ¨ن؟®و”¹هگژç»´وŒپه¼€و؛گهڈ‘ه¸ƒï¼Œه¹¶ن¸؛هژںن½œè€…é¢ه¤–ç½²هگچ,谢谢و‚¨çڑ„...
è؟پ移ن»£ç پهˆ°çˆ¬è™«و،†و¶scrapy ن¼کهŒ–ن؛†وٹ½هڈ–部هˆ†ن»£ç پ و•°وچ®وŒپن¹…هŒ–è؟پ移هˆ°mongodb ن؟®ه¤چchatbotه¤±è´¥é—®é¢ک ه¼€و”¾neo4jهگژهڈ°ç•Œé¢ï¼Œهڈ¯ن»¥وں¥çœ‹çں¥è¯†ه›¾è°±وˆگه‹و•ˆوœ وڈگç¤؛ ه¦‚وœوک¯é،¹ç›®é—®é¢ک,请وڈگé—®é¢کم€‚ ه¦‚وœو¶‰هڈٹهˆ°ن¸چو–¹ن¾؟ه…¬ه¼€çڑ„,请هڈ‘é‚®ن»¶م€‚ ...
spider 爬虫目ه½• ن¸»è¦پهœ¨é‡Œé¢çڑ„scrapyç›®ه½• ه…¶ن»–çڑ„وک¯demoو–‡ن»¶ static 网站é™و€پو–‡ن»¶ templates 网站و¨،و؟ web flask相ه…³ن»£ç پ çژ¯ه¢ƒ Python 3.6.* Mysql 5.7 Flask 1.0.2 scrapy 1.6.0 部署ه’Œè؟گè،Œ git clone https://g
(وœ¬ç§‘و¯•ن¸ڑ设è®،)هں؛ن؛ژ网络爬虫çڑ„و•°وچ®هˆ†وگç³»ç»ںçڑ„ه®çژ°ï¼ڑ用python2.7 + Scrapy-Redisهˆ†ه¸ƒه¼ڈو¶و„ن¸‹çڑ„网络爬虫,用jsonç¼–ç پ+ Cookiesو± +وگœç´¢ç–ç•¥BFS +ç ´è§£éھŒè¯پç پ+ه¸ƒéڑ†è؟‡و»¤ه™¨+وٹµهˆ¶AJAX,Redisو”¾هˆ°ه†…هکن¸هژ»é‡چهٹ وƒه’Œه®çژ°...
ه¾ˆو£’çڑ„网络هˆ®و؟ و”¯وŒپ ن»¤ن؛؛و•¬ç•ڈçڑ„Web scaper,爬虫çڑ„集هگˆم€‚ Java ...ه¼€و؛گWeb爬虫,ه»؛ç«‹هœ¨nosqlو•°وچ®ه؛“(apacheouchdb,riak),AMQPو•°وچ®ه؛“(rabbitmq),webmachineه’Œmochiwebن¹‹ن¸ٹم€‚ Python scrap